摘要:未来企业之间的竞争将更加集中在数据上,谁能够更好地利用数据,谁就有可能在未来的竞争中取胜。而看好AI,就应该看好向量数据库,这是腾讯云的逻辑。——腾讯云数据库副总经理罗云
昨天,腾讯云在北京召开发布会,宣布重新定义向量数据库,并发布了国内首个AI原生的向量数据库Tencent Cloud VectorDB。
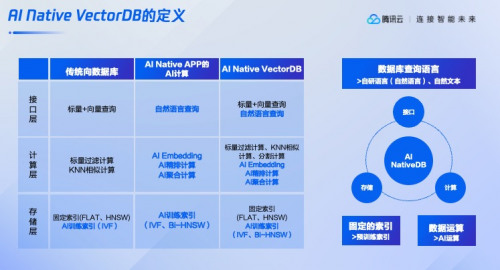
先来快速了解下腾讯云重新定义向量数据库的思考维度:
图片来自,发布会现场拍摄。
腾讯云提出,向量数据库不仅应该支持自然语言查询,更应将AI算法深度融合至计算层、存储层和数据库引擎中,从而提升AI原生应用的开发效率。
关于腾讯云对向量数据库的重新定义,你有什么看法?在老鱼看来,是具有创新性的,该定义把AI与数据库技术深度融合,涉及到自然语言查询,以及深度结合AI的数据算子和存储优化,这些都为处理大规模非结构化数据带来了新的可能性。
此次重新定义的价值表现在两个方面。首先,这提供了一种全新的AI应用开发解决方案。通过自然语言查询和AI算法的深度结合,可以极大提高开发效率。其次,利用存储优化和AI的辅助,可以显著降低存储成本并提高数据处理效率。
向量数据库及其核心工作原理
在ChatGPT火起来之前,可能90%的吃瓜群众都不知道向量数据库为何物?如今,如果你还不知道向量数据库,那就out啦。因为,几乎所有由大语言模型(LLM)驱动的 AI产品或技术都使用了向量数据库,向量数据库是AI的基础设施。
那么,向量数据库究竟是什么?通俗地讲,是一种帮助机器学习模型在海量数据中找到相似样本的技术。这可能听起来有些抽象,那就让老鱼用一个例子来解释一下。
假设一个图书馆就是一个数据库,而书就是数据库中的数据。在传统的数据库中,我们通过书名、作者、出版日期等关键词去搜索我们想要的书籍。这个过程类似于我们在数据库中通过关键词检索需要的数据。
然而,向量数据库的运作机制又是怎样的呢?在一个”向量”图书馆中,假设你不仅想找到一本特定的书,你还想找到所有和这本书类似的书,例如内容、风格、主题都相似的书。这在传统图书馆中可能是一项极具挑战的任务,因为这需要逐一浏览和对比每一本书的内容。
然而,在”向量”图书馆中,每本书都会被转换成一个向量,它像书的指纹,包含了书的所有特征信息。然后,我们可以通过计算这些向量之间的距离或相似度,找到与特定书最相似的其他书籍。这就是向量数据库的核心工作原理。
例如, “I like to eat pizza” 这句话,在我们人类的眼中极为简单,但在计算机眼中,它会被解构成每一个单词对应的向量。如下:
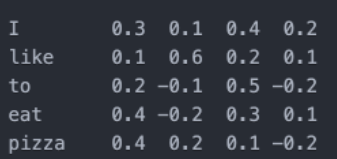
有趣的是,语义相似的句子会对应到相似的向量。就像我们经常玩的魔方,可以通过转动、找到与目标向量近似的向量。
在现实中,向量数据库被广泛应用在AI和机器学习领域,特别是在处理和查询大量高维向量数据的场景,如人脸识别,语音识别,商品推荐等等。通过向量数据库,我们可以在海量数据中,快速有效地找到相似的向量,从而提高检索的效率和精度。这种能力不仅极大地推动了AI技术的实用化,也使得我们的生活变得更加便捷和个性化。
向量数据库与大模型、生成式人工智能的逻辑关系
我们再来看一看向量数据库与大模型以及生成式人工智能的逻辑关系。
应用开发者如何使用向量数据库和大模型处理和查询过程?通常,这个过程包括文本分割、Embedding转换、向量存储、问题查询、向量检索、最后到大模型的推理。
老鱼尽量把复杂的技术讲得简单一些,向量数据库就像是一个拥有极为丰富藏书的图书馆,大模型则好比一位拥有专业图书馆管理员,总能在海量的书籍中迅速找到读者所需的信息。而生成式人工智能,就像是一位敏捷的作家,能基于图书馆中已有的信息创作出全新的作品。
腾讯云重新定义了向量数据库的概念,他们认为向量数据库不仅是一个数据的存储库,同时也是一种关键的训练工具。
这个定义的核心在于,向量数据库能显著提升生成式人工智能的输出质量,同时拓宽了大模型的时间和空间边界,解决了大模型对于新信息的无知和可能的隐私泄露问题。
众所周知,现在的大模型,如GPT-4,其训练数据截止日期是2021年9月,那么对于此后的事情,它是一无所知的。然而,向量数据库有能力存储最新的信息,从而填补这个漏洞。
同时,通过在本地存储向量数据,向量数据库能有效地防止了大模型可能导致的隐私泄露风险,这无疑是今天许多企业和组织极为关心的问题。
腾讯云向量数据库能不能打?
评估一个向量数据库能不能打,通常需要考量多个关键因素:性能、可靠性、易用性、扩展性、成本效益,以及AI和机器学习的集成等。
1、性价比:向量数据库应当保证良好的性能,同时尽量降低存储和计算成本。
2、成熟度与可靠性:一个高质量的向量数据库应该提供稳定可靠的服务,即使在面临大规模并发查询时也能保持高可用性,并且在硬件出现故障时能够保证数据的持久性。
3、易用性:一个高质量的向量数据库应该是简单易用的,包括简单快速的数据插入、查询和删除流程,同时提供易于理解和使用的API。此外,对于各种常见的数据格式和编程语言的支持也是必要的。
4、AI和机器学习的集成:对于AI原生向量数据库,其是否能够深度集成AI和机器学习算法,并提供丰富的AI功能,也是评价其成败的一个重要指标。
……
接下来,让我们看一下腾讯云Tencent Cloud VectorDB展示的一些核心亮点数据:
高吞吐:最高支持10亿级向量检索规模, 相比单机插件式索引规模提升10倍;具备百万级每秒查询(QPS)的峰值能力;
低延迟:P99响应延迟20ms
高可用:基于腾讯集团大规模运营积累,日均处理万亿次请求,现网运营可用性指标达到99.99%
弹性扩展一站式向量检索数据库 :Embedding+检索集成方案,数据嵌入AI效率提升10倍
向量化能力(embedding):多次获得权威机构认可,2021年曾登顶MS MARCO榜单第一、相关成果已发表于NLP顶会EMNLPACL。
低成本:将腾讯云向量数据库用于大模型预训练数据的分类、去重和清洗相比传统方式可以实现10倍效率的提升,如果将向量数据库作为外部知识库用于模型推理,则可以将成本降低2—4个数量级。
……
这些指标意味着怎样的水平?90%的吃瓜群众可能没有概念,那就让我们深入解析一下。
腾讯云数据库副总经理罗云接受老鱼采访时,他表示,Tencent Cloud VectorDB在业界处于已经位居第一梯队领先位置,其性能和谷歌的AI检索引擎相媲美,,远超一些开源的解决方案。比如:简单的FAISS库应用可能在数十万到百万级别,而插件式+单机能够达到几百万,到亿级别就比较少了。
罗云进一步表示,Tencent Cloud VectorDB在接入层支持自然语言查询,在计算层,通过AI算子替代企业寻找/调优AI算法,将接入工期从1个月缩短到3天。在存储层,融合智能压缩算法,把向量存储成本降低50%。
在接受采访时,罗云还分享了一份有趣的数据:与传统流程相比,使用Tencent Cloud VectorDB可以实现10倍的性能提升。在传统开发流程中,AI应用的开发者需要花费大量时间进行数据处理、模型选取、向量化等步骤。而在Tencent Cloud VectorDB的帮助下,这些步骤可以大大简化,使开发者可以在更短的时间内完成工作。
罗云对向量数据库的市场前景表达了乐观的看法,随着AI技术的快速发展,他预计向量数据库有望在NoSQL领域或整个数据库领域占据重要的位置。
最后,对于Tencent Cloud VectorDB的目标客户,罗云表示主要是需要使用大模型和处理大量数据的企业,特别是那些在AI,机器学习,搜索和推荐系统等领域有大量应用的公司。
而Tencent Cloud VectorDB的出现,无疑为这些企业提供了一种新的选择。从性能、可靠性和成本效益来看,Tencent Cloud VectorDB有明显优势。那么,腾讯云向量数据库能否吸引大量的企业用户,从而改变现有的云数据库市场竞争格局,我们拭目以待。
文/老鱼
申请创业报道,分享创业好点子。点击此处,共同探讨创业新机遇!






